Ultimate Compression Algorithms Tier List
Ever wondered how to shrink your files to an impossibly small size? You’re in the right place! This is your ultimate guide to the wild world of compression algorithms.
Stick around as we put them to the test to find the perfect one for your needs.
What on Earth is Data Compression?
In a nutshell, data compression is the magical art of encoding information using fewer bits than the original file. The main goal is to shrink files down for more efficient storage, faster network transfers, or both!
There are two main flavors of compression:
- Lossless Compression: This is like a perfect vacuum-sealed bag for your data—nothing gets lost! The decompressed file is a bit-for-bit perfect clone of the original. Common lossless wizards include
DEFLATE(used ingzip),bzip2,LZMA, andZstandard. - Lossy Compression: This one’s a bit more ruthless. It cleverly throws out some “unnecessary” data to achieve incredible compression ratios. It’s the secret sauce behind your MP3s, JPEGs, and H.264 videos, where you’d never notice the missing bits anyway.
These algorithms perform their magic using clever tricks like:
- Entropy encoding (e.g., Huffman, arithmetic coding)
- Dictionary-based compression (e.g., LZ77, LZ78)
- Prediction and context modeling (the brains behind modern beasts like Zstandard)
So, how well does an algorithm work? It all boils down to the type of data, how much redundant information it has, and the algorithm’s trade-offs between speed, memory usage, and compression ratio.
Putting the Algorithms to the Test
To see these algorithms in action, I threw a bunch of different files at them. Here are our mighty contenders:
- gzip
- bzip2
- xz
- zstd
- lz4
- brotli
- lzma (7zip)
- zip
And here are the exact versions of the tools used in my high-tech, super-scientific lab (a.k.a. my computer):
1
2
3
4
5
6
7
8
gzip 1.14-modified
bzip2, a block-sorting file compressor. Version 1.0.8, 13-Jul-2019.
xz (XZ Utils) 5.8.1
*** Zstandard CLI (64-bit) v1.5.7, by Yann Collet ***
*** lz4 v1.10.0 64-bit multithread, by Yann Collet ***
brotli 1.1.0
liblzma 5.8.1
This is Zip 3.0 (July 5th 2008), by Info-ZIP.
The Sacrificial Files
I tested the algorithms on a variety of data:
- Flight Data JSON
- OpenSSH Logs (because who doesn’t love reading logs?)
- rockyou.txt (the infamous password list)
- My personal FLAC library
Flight Data JSON
- Original File Size: 123.0 MB
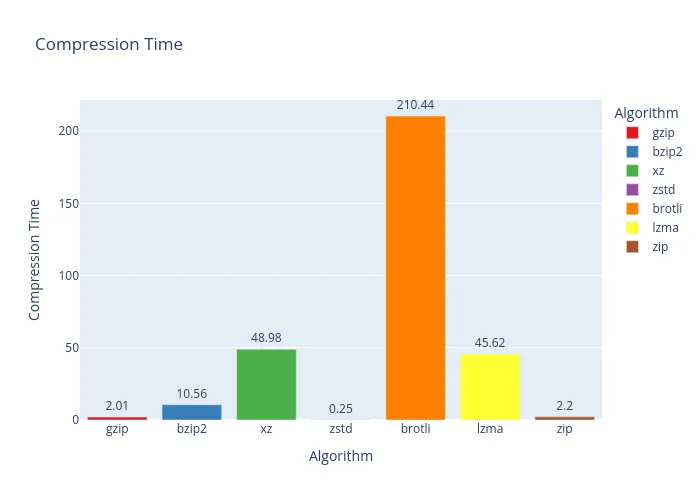
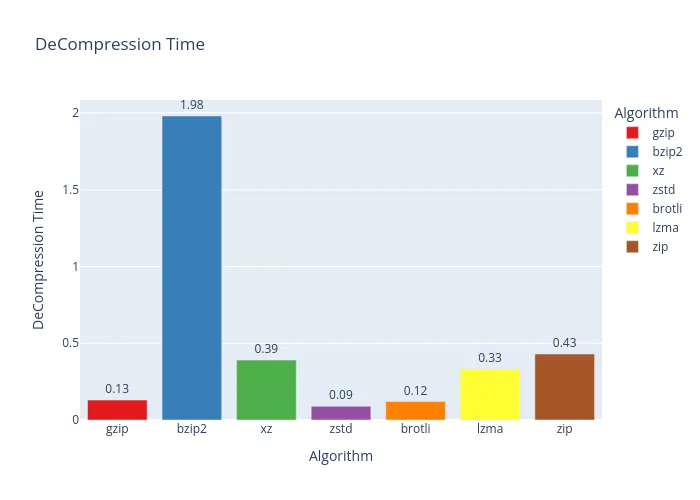
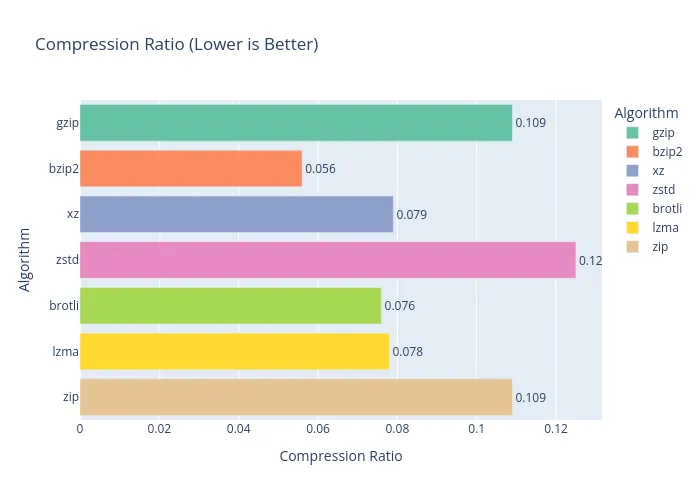
And the winner for squishing JSON is… bzip2! It delivered the best compression ratio with a respectable compression time. The only catch? Decompressing is a bit of a snoozefest compared to the others.
OpenSSH Logs
- Original File Size: 73.4 MB
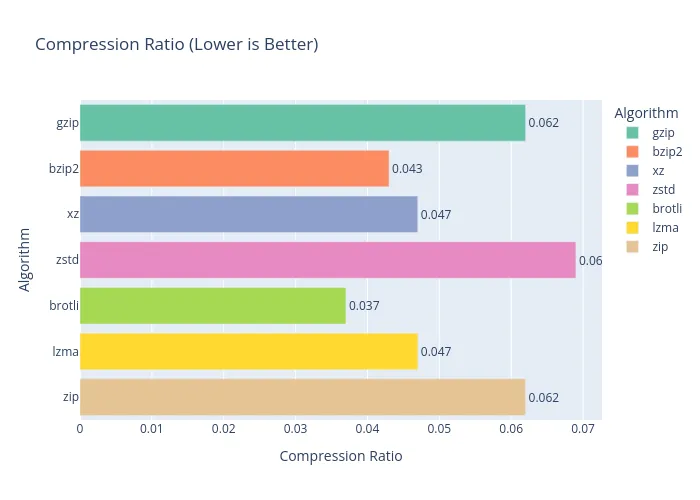
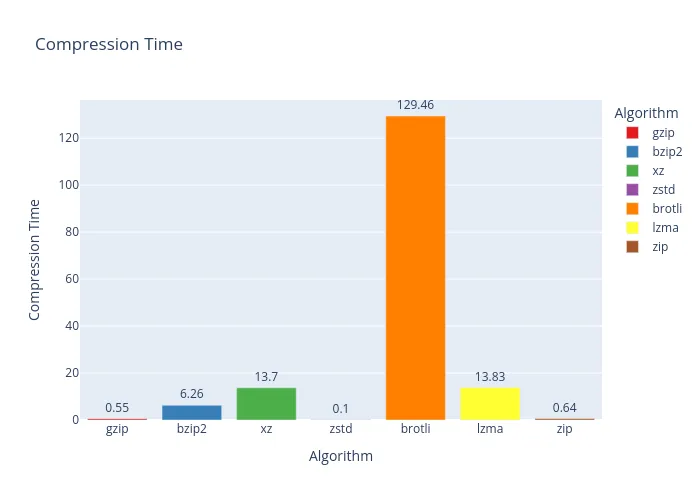
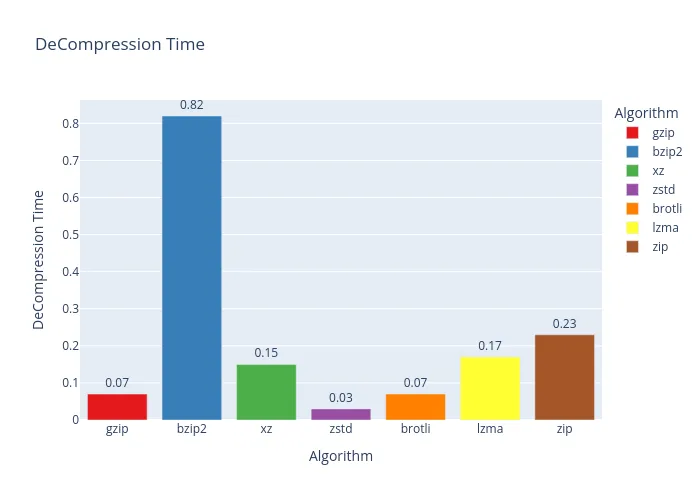
Well, look who it is again! bzip2 takes the crown once more. If I were writing a log backup script, bzip2 would definitely be my co-pilot. It seems to have a real talent for handling plain text with lots of repetition.
rockyou.txt
- Original File Size: 139.9 MB
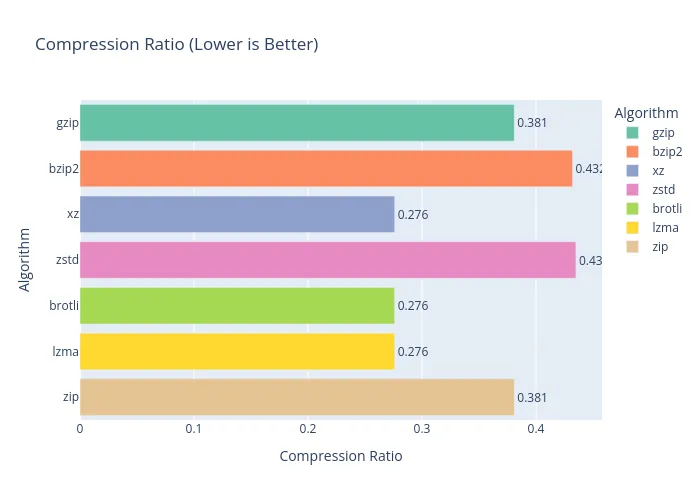
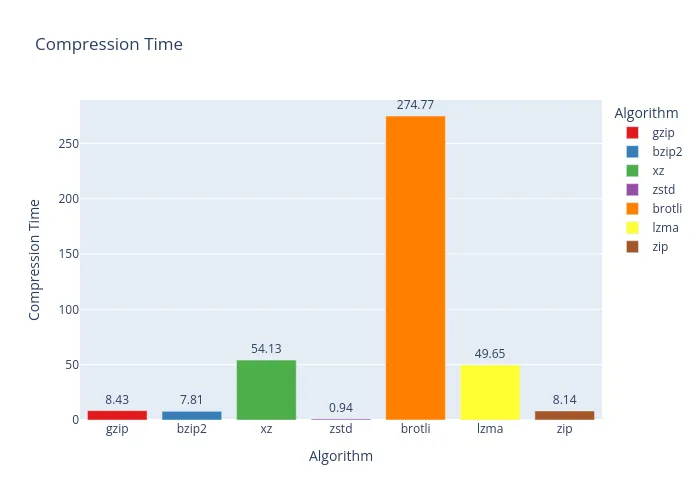
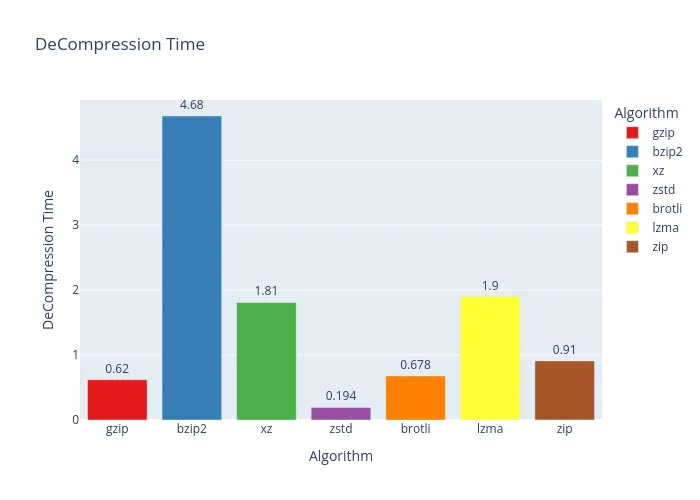
Whoa, a plot twist! On rockyou.txt, our previous champion, bzip2, completely fumbled. Its compression ratio was barely better than zstd, making it a poor choice here. zstd, on the other hand, was a speed demon! While it didn’t have the best ratio, its performance was impressive. The true winners for pure file size reduction, however, are xz and lzma.
FLAC Songs
Even though FLAC files are already compressed, I thought, “Can we go deeper?” So, I grabbed three albums from my library to find out. To make sure our algorithms could chew on them properly, I bundled the three albums into a single tar archive.
The only tool needed here was good old tar:
1
tar (GNU tar) 1.35
- Original File Size: 3.6 GB
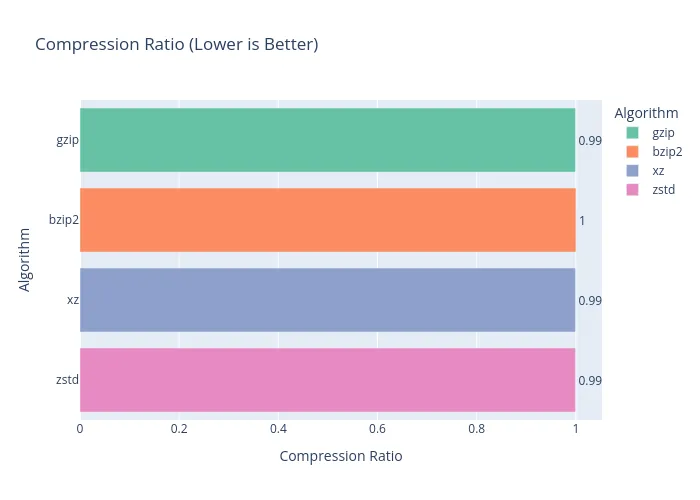
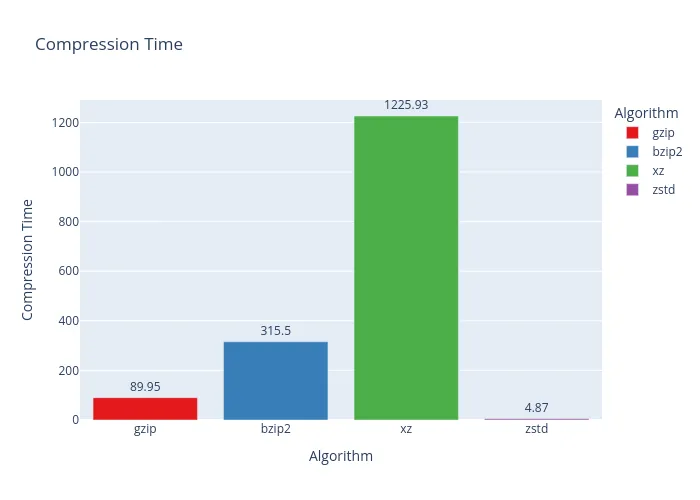
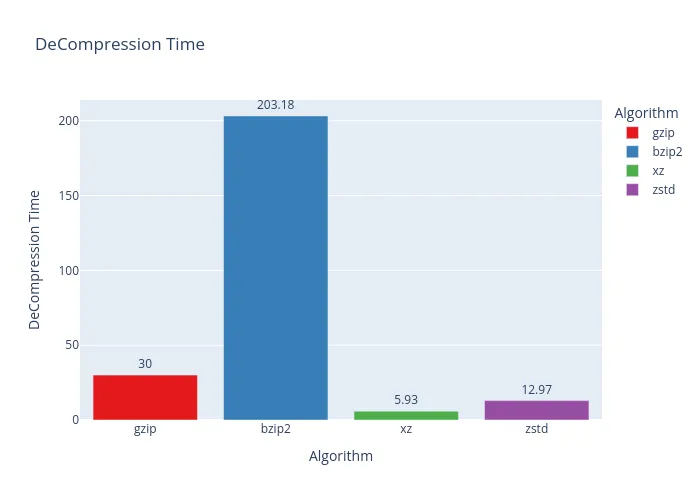
And the results are in… you can’t really compress a compressed thing much further. As the graphs clearly show, this was an exercise in futility. Take it from me: don’t try to re-compress your FLAC files unless you enjoy watching progress bars and wasting precious time.
Final Thoughts
This has been a fun and enlightening experiment. One thing is clear: using zip on Linux feels a bit dated when gzip is a superior, open-source alternative that’s already there.
My personal favorite of the bunch has to be zstd. Why? It’s FAST. Like, ridiculously fast. Picture this: you’re moving huge files across your home network. If you’re on a gigabit connection, compressing with zstd first can actually speed up the total transfer time. Less data to send means a quicker trip!
I also have a soft spot for xz, as it consistently delivered some of the smallest file sizes without being as agonizingly slow as brotli.
But hey, brotli isn’t all bad! Got a server in your homelab that’s just sitting there gathering dust? Put that CPU to work! Tell it to brotli-compress something, and it’ll be happily busy for the next month. For static web assets, that wait can be totally worth it.
Anyway, enough rambling. Here’s my personal cheat sheet for picking an algorithm:
- Sharing an archive publicly:
brotli. It’s slow to create, but browsers love it, and you only have to compress once. - For the best ratio without waiting an eternity:
xz. This is the sweet spot for great compression whenbrotliis just too slow. - For log backups and JSON files:
bzip2. It’s the king of repetitive text. - For quick, everyday compression (under 10 GB):
gzip. A fantastic, reliable all-rounder. For quick, everyday compression (over 10 GB):
zstd. When you have a massive file and speed is of the essence.- My Favorite:
zstd. I like it just because it’s fast.
Of course, these are just my recommendations. The best way to find your perfect algorithm is to look at the charts and pick the one that best fits your specific needs for speed, size, and sanity.
Thanks for reading! I hope this deep dive was useful to you.